
Six questions to evaluate data-enabled learning moats
How to tell when data-enabled learning can create defensible competitive positions.


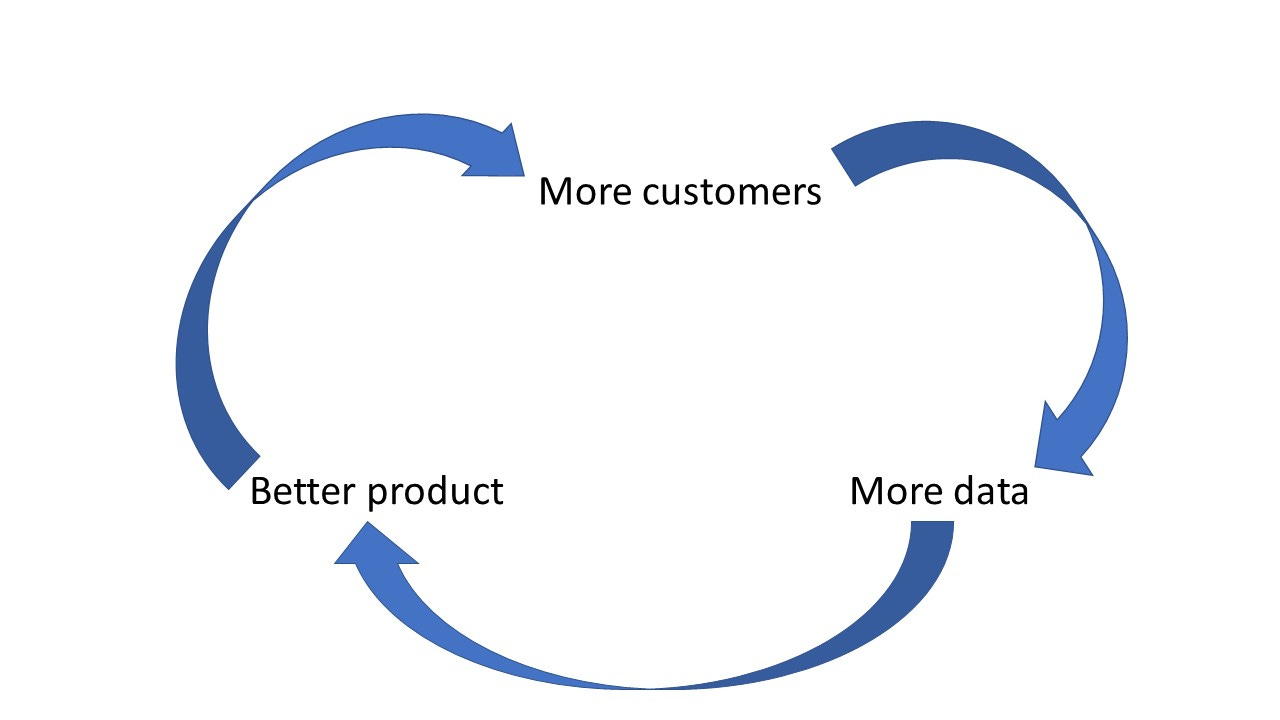
Data-enabled learning is the virtuous cycle through which a firm with more data uses that data to improve its product, thereby attracting more customers, and so more data, and so on.
Companies used to do this with surveys and focus groups, and the insights would be incorporated into the next versions of their products months or years later. Today, thanks to widespread digitization and machine learning algorithms, data-enabled learning has become much faster and more consequential. Oftentimes products and services can be improved in real time, as customers are still using them. Moreover, because the learnings may be tied to individual customer data, product improvements can now be customized.
Do these changes mean that having a lot more data gives a firm a strong competitive advantage? Not necessarily.
In this post we lay out a list of questions that we use when evaluating investment opportunities with data-enabled learning, similarly to what we did in our earlier post on the defensibility of regular network effects. The post draws on our recent 2020 academic working paper “Data-enabled learning, network effects and competitive advantage” and our guide for executives “When Data Creates Competitive Advantage” from the January-February 2020 edition of the Harvard Business Review.
In an earlier post on data network effects, we gave a long list of examples of firms and products that enjoy data-enabled learning. While some of these involved household names like Google Maps, Netflix, Spotify, and Waymo, others were fast growing tech startups. Indeed, the majority of the startups we evaluate these days point to data and AI as a source of long-term defensibility that they hope to benefit from.
Here goes our list of questions.
1. How important is the value of learning from customer data relative to the standalone value of the product?
For example, smart TVs may be able to collect voluminous amounts of data on TV watching habits, and in the future use those to give recommendations about what shows to watch. But when buying TVs, consumers are likely to place a lot more weight on superior picture quality and larger screen size than on show recommendations. This makes it unlikely that data-enabled learning will afford incumbent TV brands much advantage. By contrast, the data and recommendation engine that powers TikTok is arguably the primary factor behind its success. As more and more products become “smart”, this is an increasingly important question to ask, as many of them will probably be closer to smart TVs than to TikTok in terms of how much value is added by data-enabled learning.
2. How quickly does the marginal value of data-enabled learning decrease?
In some contexts, the value of learning generated from additional usage diminishes significantly after a modest amount of data has been collected. This makes it easier for rival companies to close the gap by generating the modest level of usage required to achieve most of the value from learning. For instance, smart thermostats quickly learn a user’s temperature preferences throughout the day, and as a result, data-enabled learning can’t provide much competitive advantage. This helps explain why Nest (acquired by Google in 2014), the first producer of smart thermostats, now faces significant competition from the likes of Ecobee and Honeywell.
A key reason why the marginal value of data-enabled learning may remain high is the importance of edge cases. Edge cases are scenarios that happen infrequently, such as a dust storm in the case of autonomous vehicles, or an unusual search query in the case of online search. The ability to handle edge cases may not be very important for some applications (recommending what movie to watch) but may be critical for others (such as autonomous vehicles or advances in rare diseases).
We can capture the points from these first two questions in the following graph, which shows two ways in which the value of learning from customer data may increase with usage.

Even though the total value of learning is the same for the two curves, the linear curve in which the value of learning from additional usage remains high throughout should provide a stronger competitive advantage for the firm that is ahead. The reason is that for the other, highly concave curve, one can obtain most of the value of learning with a much lower level of usage, and so it is easier for a new entrant to get within striking distance.
3. How fast does the relevance of user data depreciate?
For the effective value of learning from data to remain high, it should be that the value obtained from the data does not depreciate too quickly relative to the speed at which the company learns from new data generated from its existing customers. If data depreciates quickly, the firm that is ahead cannot accumulate a lasting advantage.
For example, all the data on search engine queries and users that Google has accumulated over decades remains valuable today. Although searches for some terms may become rare over time while searches for new ones might start appearing more frequently, having years of historical search data is of undeniable value in serving today’s users. By contrast, the value of learning from user data tends to decrease quickly when it comes to social games, which are subject to fads and quick changes in user preferences over time.
4. How hard is it to copy product improvements that are based on customer data?
If data-enabled learning leads to product improvements that are publicly observable, a rival can provide the same features without needing the data. This is true for a variety of software products, where the design features based on learning from customer usage can be easily observed and copied. Contrast this with product improvements that are hidden or deeply embedded in a complex production process, which makes them hard to replicate by rivals. For example, when a firm obtains detailed feedback on its call center staff and calls from its customers, it can improve its call center performance (e.g. assigning more experienced staff to more difficult calls, targeting feedback and training to underperforming staff), and there is no way for these improvements to be copied by a rival firm that is entering the market.
5. How difficult/expensive is it to acquire alternative sources of data?
Sometimes, new entrants can overcome their handicap in customer data if there exist alternative sources of data that are relatively easy or inexpensive to obtain and that can be used to train their algorithms, thereby improving their products to the point where they can start attracting customers organically. For instance, there are many firms that leverage AI to offer conversion services from audio and video to text. The reason it is difficult for any one firm to build a highly defensible competitive position in this space is that there are many publicly available data sources (e.g. captioned YouTube videos, Netflix shows and movies) that can be used to train speech recognition algorithms without any customers. On the other hand, it is much harder to compete with a recommender system like the one powering TikTok because it takes advantage of the unique nature of its users’ preference data and there is no good substitute dataset to deliver recommendations to those users.
While large existing datasets can sometimes be valuable, at other times they are not because of subtle (but important) nuances in the way data is used across different applications. For this reason, there can also be a tendency to exaggerate the ability of companies with large existing data sets to leverage that data to new applications. Consider x.ai, which provides an AI agent that helps set up meetings by communicating with human contacts via email. One might think that Google’s massive amount of data from Google Calendar, Gmail and search would give it an unfair advantage in this space. But in the words of x.ai’s founder, Dennis Mortensen, discussing whether Google’s vast data set poses a threat to x.ai: “They actually have no data set, as in zero. Nothing. Because there is no agent human negotiation … that exists in that data set. And you can’t label it in the past, as in, what if the agent said this, what would the human then say. So you have to then go out and say now the agent says this to a human, what is the response --- that becomes part of your training data set.”
6. Is the learning from user data “within user” or “across users”?
Within-user learning refers to cases in which a firm’s learning from each user’s history is only relevant to that user. For example, smart connected devices (e.g. thermostats) rely mostly on within-user learning. Such within-user learning is good from a firm’s perspective because customization creates a switching cost for existing customers, making it less likely they will switch to a competitor having spent time using a product. But this does not provide the firm with an advantage in competing for new customers, which it would only get in the presence of across-user learning, i.e. the learning from one customer helps improve the product for other customers too. Needless to say, ideally one would want to see both across-user and within-user learning – it is the combination of the two that provide the most defensibility for firms.
In conclusion, as even the most mundane consumer products become smart and connected (e.g. smart forks, yoga mats and pants), data-enabled learning will be used to enhance and personalize more and more offerings. However, their providers won’t build strong competitive positions unless the value added by customer data is and will remain high, the data is proprietary, admits few substitutes, and leads to product improvements that are hard to copy. And as seems to have happened with speech recognition services, it is also possible that entirely new algorithms (sometimes pre-trained on publicly available data) might arise that eliminate a firm’s data advantage altogether.
If you enjoyed reading this, sign up now so you will receive our posts directly in your inbox as they are published.
In the meantime, tell your friends!