
Why are data network effects less valuable than regular network effects?
Relative to regular network effects, data network effects are easier to circumvent, costlier to maintain, and tend to run out of steam faster.


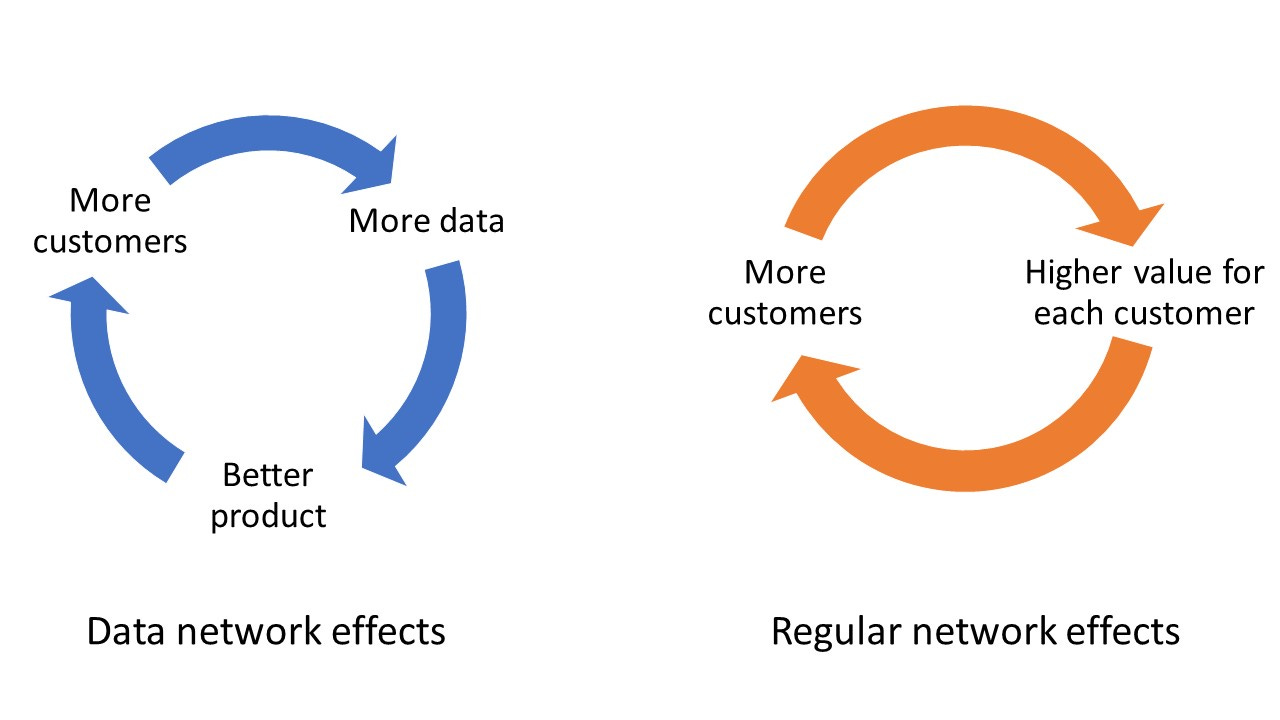
Companies with more data can use that data and machine learning algorithms to produce a superior product, allowing them to attract more customers, from which they gather more data, and so on. This virtuous cycle, known as “data-enabled learning”, is playing out in an ever-increasing array of digital and cloud-based products and services.
Examples include Google Maps and Waze (traffic predictions improve with more drivers using them), Netflix, Stitchfix, Spotify, Tinder, TikTok, and TrueFit (recommendations improve with more users/usage), speech recognition software, virtual assistants, and chat bots (accuracy improves with more individual usage and/or more users), smart connected devices like the Nest thermostat or the Eight Sleep bed (customization improves with more individual usage), autonomous vehicle systems like those being developed by Cruise, Mobileye and Waymo (accuracy improves with more usage and testing), etc. By now, we’ve seen data-enabled learning examples in practically every sector, cutting across fields as diverse as farming (Prospera), healthcare (Notable Labs), law (Luminance) and security (Vaak).
There is a widespread tendency to assume that data-enabled learning necessarily creates data network effects, and to equate the latter with regular network effects (see our post about regular network effects and their defensibility). This sometimes leads to exaggerated claims of defensibility based on data-enabled learning.
Part of the confusion, in our view, arises because many large tech companies that are built around platforms with network effects (e.g. Airbnb, Alibaba, Amazon, Facebook, Google) also have access to valuable data that enhances their existing network effects. In such cases, the strong competitive positions these companies already enjoy from network effects may be incorrectly (or excessively) attributed to their data.
Another source of confusion is that in some cases, what might seem like data-enabled learning leading to network effects is actually just regular network effects at play. For example, data-enabled learning is not present when users directly share information with each other (e.g. user reviews on TripAdvisor and Yelp, user-generated playlists on Spotify, user questions and answers on Quora and Stack Overflow). In such cases, the more such users there are, the more information will be shared and so the more valuable the service becomes. This is a regular network effect – users value directly being able to interact with more other users, where the interaction here involves sharing information or reviews about products and services. Such network effects are potentially quite powerful, but need not enhance a company’s ability to learn from its customers’ data.
Focusing on situations where true data-enabled learning is at play, data network effects only arise to the extent that the learning is across users. In other words, what is learnt from some users must translate to the firm being able to offer a better experience for other users. This is in contrast to within-user learning, which means learning from any given user’s history is only relevant to that user. For example, smart connected devices (e.g. thermostats) rely mostly on within-user learning. Such within-user learning may create switching costs, but it does not create anything like a network effect.
However, even when they exist, data network effects are usually not as long-lasting and defensible as regular network effects. There are several reasons.
First, there are usually many more ways around data network effects than regular network effects. Buying data is generally easier than acquiring customers. With data network effects, customers don’t care about the presence of other customers per se, so it is usually possible to at least partially compensate for a smaller customer base by acquiring alternative sources of data and/or developing better algorithms. This means the cold-start problem is less severe and challengers have an easier time catching up to incumbents than in the case with regular network effects, where the only way to catch up is to get more customers.
Second, in many cases data network effects run out of steam after attracting a relatively small number of customers. This may be because with improvements in algorithms, it does not take a lot of data to extract most of the valuable learning. Or, even when large amounts of customer data are necessary, sometimes that data can be obtained from just a few large business customers (e.g. a few big farms, hospitals or law firms, depending on the application). This can be a lot easier to achieve than attracting the large number of customers that would typically be required under network effects. In some applications (e.g. speech recognition), dramatic improvements in AI and the emergence of publicly available datasets have reduced the need for unique customer data to the point where the value of data-enabled learning has largely disappeared. Regular network effects, on the other hand, extend further and are more resilient: an additional customer still typically enhances value for existing customers (who can interact or transact with him or her), even when the number of existing customers is already large.
Third, self-reinforcing user expectations are less likely to play a role with data network effects. With regular network effects, when choosing which firm to buy from, customers have a direct reason to care about what other customers will do in the future, because that will directly affect the benefit they get. For instance, such expectations play an important role in the adoption choices for new videogame consoles. Every user wants to buy the console that she expects will attract a larger number of high-quality games and that will be adopted by a larger number of her friends. Such expectations usually favor incumbents and can make it challenging for a new entrant to break into the market. In contrast, with data network effects, the mechanism by which a product gets better when more customers adopt is less direct and therefore less likely to be well understood by users, particularly in B2C contexts. Thus, users are more likely to behave myopically with data network effects, just basing their decision on a comparison of the value offered by the firms’ current offerings. And by being myopic, present users looking to buy a product and use it for some time will end up underestimating how much better an incumbent’s product would get relative to a challenger’s if all future users were to join the incumbent. This means, other things being equal, it is easier for a new entrant to attract users and compete with data network effects than with regular network effects.
Fourth and finally, to produce lasting data-enabled network effects, a firm has to keep putting in work to learn from customer data. This work can include the ongoing tasks of gathering, cleaning, securing and processing data, as well as improving algorithms to remain competitive. In contrast, as one of us remembers Intuit cofounder Scott Cook saying, “products that benefit from [regular] network effects get better while I sleep.” Indeed, with regular network effects, interactions between customers can continue to create value even if the firm stops innovating. For example, even if a new online site for classifieds offered buyers and sellers objectively better features than Craigslist does (not a hard task), it would still have to contend with Craigslist’s network effects—buyers prefer going to the online classifieds site where most sellers are and vice versa. Of course, even regular network effects require some maintenance work (e.g. minimizing fraud or abuse by ill-intentioned participants). We would certainly not recommend firms fall asleep, but rather they should continue to make investments in improving the quality of the interactions enabled. Still, once in motion, the self-reinforcing mechanism associated with regular network effects usually requires less fuel provided by the firm than the one associated with data network effects.
For all these reasons, from an investment perspective, we generally prefer firms built on regular network effects to those built on data network effects. Needless to say, data network effects can be very powerful too, and our ideal companies to invest in have both.
If you enjoyed reading this, sign up now so you will receive our posts directly in your inbox as they are published.
In the meantime, tell your friends!
I agree with Roger Pena: "This is an excellent, excellent article." By contrasting data network effects with regular network effects, it succinctly paints a very clear picture of both.
Dave Duchesneau, CTO
Scrutiny, Inc.
Andrei Hagiu and Julian Wright
This is an excellent, excellent article. Could not agree any more with this perspective and view. This article fits perfect into what is going on in the IoT market space as of today. Most companies are trying to build valuable data driven business modeled outcomes for their given market space into IoT, instead of focusing on the networking enabled interactions between machines to machines and machines to people. Spending years of research into IoT, this is something I have never understood on why companies focus on data driven model first in IoT, vrs the enablement of continuous scalable networking interaction to IoT. Big Data will follow in accordance to how these interactions play out as the ecosystems scales. Which in turn, makes the ecosystem more valuable to both users of the ecosystem: machines and people. What the history shows is that there is a cap to the scale of these ecosystem to be created in these data driven models in IoT. Nest, Smart meters, and to be next in line will be the smart speaker. I came across a stat in listening to the book "Bezonomics, by Brian Dumaine" that stated that for every smart speaker sold for the home there is 1 to 2 accessories or devices bought to extend the speaker's capabilities, nothing beyond that. In my opinion this points to your article.
Just my added thoughts.
Nice work!